

By OSCAR MACKERETH
OpenAI is a San Francisco-based artificial general intelligence (AI) research laboratory, consisting of the for-profit corporation OpenAI LP and its parent company, the non-profit OpenAI inc.
In November 2022, OpenAI released its flagship product for public testing: ChatGPT, which operates through the GPT3 large language model. ChatGPT is the largest neural network ever created and the latest iteration of the Generative Pre-Trained Transformer series (GPT-n). The GPT-n models are auto-regressive language models[1] which utilise deep learning to produce human-like text, known as ‘natural language processing’ (NLP). These models have the potential to perform tasks such as question answering, textual entailment and summarisation with little-to-no training.
Figure 1: ‘The Potential of OpenAI’ – DALL·E 2
Last month, Semafor reported that after an initial US$1bn investment in 2019, Microsoft was set to inject US$10bn more into OpenAI[2], valuing the firm at US$29bn. These are large figures for a firm which has not presented a commercial business model and is in a heavy investment phase. OpenAI is attracting considerable curiosity from many sources, somewhat against the grain of today’s environment which has become more questioning of visionary pilot projects from the Technology sector.
In exchange for its significant investment, Microsoft, a Cerno Global Leader company, will receive 75% of OpenAI’s profits until it recoups its investment and retain a 49% ownership following that threshold. However, the principal driver of the investment appears to be Microsoft’s efforts to maintain its position at the forefront of cutting edge of AI. By doing so, it aims to pioneer the commercialisation of the OpenAI models and create synergies between its pre-existing technological ecosystem and the next generation of consumer technology.
GPT-n
The GPT model was first proposed in ‘improving language understanding by Generative Pre-Training’ by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever[3]. Prior to this, most NLP models were trained in a supervised manner, requiring large amounts of annotated data for learning a particular task and failing to generalise for tasks other than what they have been trained for. This paper proposed a generative language model which was able to analyse the unannotated data by providing examples of specific downstream tasks, such as classification, sentiment analysis and textual entailment.
GPT1 was built using the language model proposed in this paper in 2018 and proved that pre-training could result in superior outputs compared to most of its supervised predecessors through ‘zero-shot capabilities’[4]. Theoretically, with appropriate scale, it could gain the capability to accurately perform NLP tasks with minimal interventions.
The significance of this was well understood by the AI community. Investors and technicians were quick to consider both the technology’s potential impact, and how to hasten the technology’s development. However, GPT1 showed that the efficacy of these models would progress in conjunction with the size of the data set and number of parameters used in pre-training. The compute power necessary to achieve technical terminal velocity is enormous and inaccessible to the Silicon Valley investors who would typically fund similar start-ups.
Thus, in 2019, Microsoft made use of its financial and technological heft, making its first investment into OpenAI. It committed US$1bn in return for securing a role as the platform upon which OpenAI would develop its models and giving it first commercial rights to the technology.
In the following year, Microsoft announced the completion of one of five publicly disclosed supercomputers in the world[5], built exclusively for OpenAI to train its neural network models. Today, the Voyager-EUS2 is still the 14th most powerful publicly known computer in existence[6], capable of 30.05 petaFLOPS (floating points operations per second), which equates to roughly 15,025x the computing power of the latest iPhone 14 Pro.
This leap in compute power drove OpenAI’s progression from GPT-1 through to GPT-3.
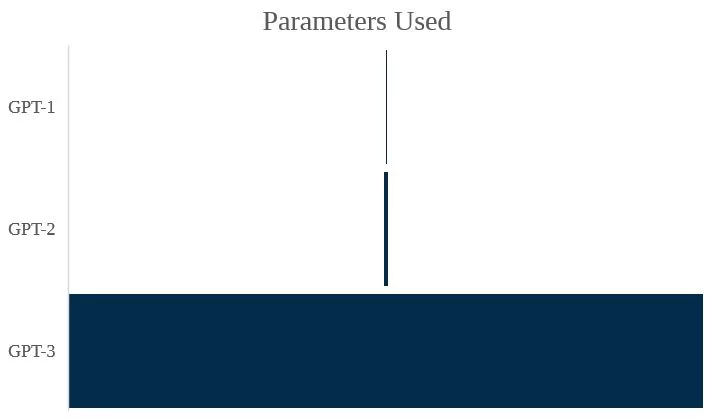 GPT-2 was trained using a data set roughly 1,000 times larger than that of GPT-1, utilising roughly 1.5 billion parameters in comparison to GPT-1’s 117 million. This resulted in material improvements in its zero-shot capabilities, vastly increasing its capability to understand and execute novel tasks.
GPT-2 was trained using a data set roughly 1,000 times larger than that of GPT-1, utilising roughly 1.5 billion parameters in comparison to GPT-1’s 117 million. This resulted in material improvements in its zero-shot capabilities, vastly increasing its capability to understand and execute novel tasks.
However, the most significant finding was that whilst the model was increasing in capacity, it was concurrently decreasing in training complexity and cost per parameter, with no sign of saturation. In short, this showed that the GPT model would only improve with another proportionate increase in scale.
Thus, OpenAI once again implemented greater scale into the GPT-3 model, using roughly 117 times more parameters than its predecessor’s 175 billion. GPT-3 succeeds in performing tasks in few- and zero-shot settings, regularly outperforming both specifically trained models and humans in tasks such as arithmetic addition, text synthesis, news general article, learning and using novel words and producing conversation.
Commercial integration
The commercial implications of this technology are vast. To quote David Friedberg, ‘old business models will not make sense in a world where software is no longer restricted to information retrieval and display’[7]. The ability to accurately retrieve, synthesise and reformat data from multiple sources with no pre-training has the potential to disrupt many computer-based productivity tools used for intellectual labour.
However, we would be remiss to suggest that the impact of this technology will only be experienced in the transmission from software services from information retrieval to synthesis. Technological innovations often generate consequences for industries adjacent to their most obvious use cases. For example, the utilisation of AI in maps didn’t just facilitate easier navigation as a society. It has fundamentally changed society by facilitating a plethora of start-ups, with mobility and micro-mobility companies such as Uber and Lime Bike, food delivery organisations such as Deliveroo, and travel companies such as Trivago.
OpenAI is already developing alternative generative models focused on image generation[8], colloquial conversation[9] and visual learning[10]. And in November 2022, a ‘multi-year collaboration’ was announced between Microsoft and Nvidia, to build a new supercomputer to help train and deploy new AIs, requiring even greater computation capabilities[11].
Thus, we should not limit ourselves to believing that the impact of these models will be limited to that which is immediately obvious. Already, Generative AI models have been used for designing new proteins[12], generating code[13],[14], advising healthcare patients[15] and graphic design[16]. In the last month alone, GPT3 has become a co-author of a published peer-reviewed paper[17], passed a Wharton MBA exam[18], the United States Medical Licensing Examination[19], and started a podcast with venture capitalist Reid Hoffman[20].
However, the cost of building computers of adequate performance and training models of necessary scale likely registers in the billions. Moreover, answering a query through ChatGPT is estimated to cost over 7x times that of a typical Google search[21],[22]. Without support, start-ups such as OpenAI are likely restricted to research and model design. Thus, we are met with the concerning reality that the economic moat of mega-cap tech players may allow them to operate in this space with little competition. Tech corporations becoming both the foundation and owners for the next generation of AI technology should plausibly concern both the public and regulators alike.
Despite this, generative AI models present a clear investment case in their capability to reorient compute productivity tools and the intellectual labourers who use them. The digitisation of corporations is a mega-trend which we believe will be fundamental to society.
The Global Leaders portfolio holds companies which are fundamental to this technology. As mentioned above, Microsoft has become a key investor. Both the Global Leaders and Pacific portfolios are well exposed to the semi-conductor industry[23] through companies such as ASML, TSMC, Samsung Electronics, Tokyo Electron and Disco Corp. These will likely benefit as key ‘picks and shovels’ beneficiaries, facilitating the leaps of compute power necessary for this technology to be properly integrated. Similarly, the Select portfolio holds the Digital 9 Infrastructure fund, driving greater global connectivity through investing in core digital infrastructure assets.
In 2006, Clive Humby claimed that “data is the new oil” after designing Tesco’s Clubcard loyalty scheme, with Michael Palmer developing the metaphor by noting that both data and crude are “valuable, but if unrefined, cannot be used”[24].
The analysis of large data sets allows businesses to contextualise consumer behaviours to their marketplace. Thus, through structuring these data sets, they turn into indispensable assets which can be utilised to enhance business outcomes. Indeed, trading in data is the premise which drove Tech giants such as those contained within the FAANG[25] acronym, to their positions of prominence. Therefore, secondary beneficiaries will likely be those who hold large and unique data sets, upon which new models can be trained to develop greater customer insight and facilitate rapid data-driven feedback.
Examples within the Global Leaders portfolio would be Visa, Zimmer Biomet, Accenture, Rockwell, Ansys and Thermo Fisher. Within the Pacific portfolio intellectual property is a key investment consideration, meaning nearly all companies could stand to benefit from the deployment of the technology. However, some key examples would be Trip.com, CSL ltd, Advantech, Hangzhou Tigermed and Sysmex. All these companies both utilise and produce vast data sets in their daily operations and may have the opportunity to optimise their extraction of value from those assets.
[1] An auto-regressive model is one which predicts future outputs, using past inputs and contextual analysis. In a language context, this means that they will guess the next word, having read all previous ones.
[2] https://www.semafor.com/article/01/09/2023/microsoft-eyes-10-billion-bet-on-chatgpt
[3] https://s3-us-west-2.amazonaws.com/OpenAI-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
[4] Zero shot learning refers to the ability of a model to perform a task without having seen any example of that kind in the past.
[5] https://news.microsoft.com/source/features/AI/OpenAI-azure-supercomputer/
[6] https://www.top500.org/system/180024/
[7] https://www.youtube.com/watch?v=kiMTRQXBol0&ab_channel=All-InPodcast
[8] https://OpenAI.com/dall-e-2/
[9] https://OpenAI.com/blog/whisper/
[10] https://OpenAI.com/blog/vpt/
[11] https://nvidianews.nvidia.com/news/nvidia-microsoft-accelerate-cloud-enterprise-AI
[12] https://www.sciencedirect.com/science/article/pii/S1367593121000508?via%3Dihub
[13] https://AI.googleblog.com/2022/07/ml-enhanced-code-completion-improves.html
[14] https://github.blog/2022-09-07-research-quantifying-github-copilots-impact-on-developer-productivity-and-happiness/
[15] https://catalyst.nejm.org/doi/full/10.1056/CAT.20.0230
[16] https://www.bigtechwire.com/2022/10/12/microsoft-designer-is-a-new-graphic-design-app-with-AI-tech-including-dall%E2%88%99e-2-by-OpenAI/#:~:text=Services-,Microsoft%20Designer%20is%20a%20new%20graphic%20design%20app%20with%20AI,%E2%88%99E%202%20by%20OpenAI&text=Along%20with%20the%20new%20Surface,postcards%2C%20graphics%2C%20and%20more.
[17] https://pubmed.ncbi.nlm.nih.gov/36549229/
[18] https://mackinstitute.wharton.upenn.edu/2023/would-chat-gpt3-get-a-wharton-mba-new-white-paper-by-christian-terwiesch/
[19] https://www.medrxiv.org/content/10.1101/2022.12.19.22283643v2.full-text
[20] https://www.sciencedirect.com/science/article/pii/S1367593121000508?via%3Dihub
[21] https://www.cnbc.com/2023/01/10/how-big-a-threat-is-chatgpt-to-google-morgan-stanley-breaks-it-down.html
[22] https://twitter.com/sama/status/1599671496636780546?s=46&t=ipYLU4U5vxgXzW-caa8emQ
[23] https://cernocapital.com/semiconductors-evolution-of-the-worlds-most-critical-manufactured-good
[24] https://ana.blogs.com/maestros/2006/11/data_is_the_new.html
[25] Meta (formerly known as Facebook), Amazon, Apple, Netflix, and Alphabet (formerly known as Google)